mirror of
https://github.com/AbdBarho/stable-diffusion-webui-docker.git
synced 2026-03-21 20:44:47 +01:00
Merge branch 'master' into 2-beta
This commit is contained in:
commit
a2f152a1cf
|
|
@ -3,3 +3,4 @@
|
|||
set -Eeuo pipefail
|
||||
|
||||
find services -name "*.sh" -exec git update-index --chmod=+x {} \;
|
||||
find .devscripts -name "*.sh" -exec git update-index --chmod=+x {} \;
|
||||
|
|
|
|||
9
.devscripts/migratev3tov4.sh
Executable file
9
.devscripts/migratev3tov4.sh
Executable file
|
|
@ -0,0 +1,9 @@
|
|||
#!/bin/bash
|
||||
|
||||
set -Eeuo pipefail
|
||||
|
||||
echo "Moving everything in output to output/old..."
|
||||
mv output old
|
||||
mkdir output
|
||||
mv old/.gitignore output
|
||||
mv old output
|
||||
28
.github/ISSUE_TEMPLATE/bug.md
vendored
28
.github/ISSUE_TEMPLATE/bug.md
vendored
|
|
@ -1,10 +1,9 @@
|
|||
---
|
||||
name: Bug
|
||||
about: Report a bug
|
||||
title: ''
|
||||
title: ""
|
||||
labels: bug
|
||||
assignees: ''
|
||||
|
||||
assignees: ""
|
||||
---
|
||||
|
||||
<!-- PLEASE FILL THIS OUT, IT WILL MAKE BOTH OF OUR LIVES EASIER -->
|
||||
|
|
@ -14,28 +13,27 @@ assignees: ''
|
|||
- [ ] It is not in the [FAQ](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/FAQ), I checked.
|
||||
- [ ] It is not in the [issues](https://github.com/AbdBarho/stable-diffusion-webui-docker/issues?q=), I searched.
|
||||
|
||||
|
||||
**Describe the bug**
|
||||
|
||||
<!-- tried to run the app, my cat exploded -->
|
||||
|
||||
|
||||
**Which UI**
|
||||
|
||||
hlky or auto or auto-cpu or lstein?
|
||||
|
||||
auto or auto-cpu or invoke or sygil?
|
||||
|
||||
**Hardware / Software**
|
||||
- OS: [e.g. Windows 10 / Ubuntu ]
|
||||
- OS version: <!-- on windows, use the command `winver` to find out, on ubuntu `lsb_release -d` -->
|
||||
- WSL version (if applicable): <!-- get using `wsl -l -v` -->
|
||||
- Docker Version: <!-- get using `docker version` -->
|
||||
- Docker compose version: <!-- get using `docker compose version` -->
|
||||
- Repo version: <!-- tag, commit sha, or "from master" -->
|
||||
- RAM:
|
||||
- GPU/VRAM:
|
||||
|
||||
- OS: [e.g. Windows 10 / Ubuntu 22.04]
|
||||
- OS version: <!-- on windows, use the command `winver` to find out, on ubuntu `lsb_release -d` -->
|
||||
- WSL version (if applicable): <!-- get using `wsl -l -v` -->
|
||||
- Docker Version: <!-- get using `docker version` -->
|
||||
- Docker compose version: <!-- get using `docker compose version` -->
|
||||
- Repo version: <!-- tag, commit sha, or "from master" -->
|
||||
- RAM:
|
||||
- GPU/VRAM:
|
||||
|
||||
**Steps to Reproduce**
|
||||
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
3. Scroll down to '....'
|
||||
|
|
|
|||
5
.github/workflows/docker.yml
vendored
5
.github/workflows/docker.yml
vendored
|
|
@ -14,12 +14,11 @@ jobs:
|
|||
matrix:
|
||||
profile:
|
||||
- auto
|
||||
- hlky
|
||||
- lstein
|
||||
- sygil
|
||||
- invoke
|
||||
- download
|
||||
runs-on: ubuntu-latest
|
||||
name: ${{ matrix.profile }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
# better caching?
|
||||
- run: docker compose --profile ${{ matrix.profile }} build --progress plain
|
||||
|
|
|
|||
36
.github/workflows/xformers.yml
vendored
36
.github/workflows/xformers.yml
vendored
|
|
@ -1,36 +0,0 @@
|
|||
name: Build Xformers
|
||||
|
||||
on:
|
||||
workflow_dispatch: {}
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 180
|
||||
container:
|
||||
image: python:3.10-slim
|
||||
env:
|
||||
DEBIAN_FRONTEND: noninteractive
|
||||
XFORMERS_DISABLE_FLASH_ATTN: 1
|
||||
FORCE_CUDA: 1
|
||||
TORCH_CUDA_ARCH_LIST: "6.0;6.1;6.2;7.0;7.2;7.5;8.0;8.6"
|
||||
NVCC_FLAGS: --use_fast_math -DXFORMERS_MEM_EFF_ATTENTION_DISABLE_BACKWARD
|
||||
MAX_JOBS: 4
|
||||
steps:
|
||||
- run: |
|
||||
apt-get update
|
||||
apt-get install gpg wget git -y
|
||||
wget https://developer.download.nvidia.com/compute/cuda/repos/debian11/x86_64/cuda-keyring_1.0-1_all.deb
|
||||
dpkg -i cuda-keyring_1.0-1_all.deb
|
||||
apt-get update
|
||||
apt-get install cuda-nvcc-11-8 cuda-libraries-dev-11-8 -y
|
||||
|
||||
export PIP_CACHE_DIR=$(pwd)/cache
|
||||
pip install ninja install torch --extra-index-url https://download.pytorch.org/whl/cu113
|
||||
|
||||
pip wheel --wheel-dir=data git+https://github.com/facebookresearch/xformers.git@3633e1afc7bffbe61957f04e7bb1a742ee910ace#egg=xformers
|
||||
- name: Artifacts
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: xformers
|
||||
path: data/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl
|
||||
13
LICENSE
13
LICENSE
|
|
@ -87,16 +87,3 @@ processes, such as predicting an individual will commit fraud/crime
|
|||
commitment (e.g. by text profiling, drawing causal relationships between
|
||||
assertions made in documents, indiscriminate and arbitrarily-targeted
|
||||
use).
|
||||
|
||||
|
||||
|
||||
By using this software, you also agree to the following licenses:
|
||||
https://github.com/CompVis/stable-diffusion/blob/main/LICENSE
|
||||
https://github.com/sd-webui/stable-diffusion-webui/blob/master/LICENSE
|
||||
https://github.com/invoke-ai/InvokeAI/blob/main/LICENSE
|
||||
https://github.com/cszn/BSRGAN/blob/main/LICENSE
|
||||
https://github.com/sczhou/CodeFormer/blob/master/LICENSE
|
||||
https://github.com/TencentARC/GFPGAN/blob/master/LICENSE
|
||||
https://github.com/xinntao/Real-ESRGAN/blob/master/LICENSE
|
||||
https://github.com/xinntao/ESRGAN/blob/master/LICENSE
|
||||
https://github.com/cszn/SCUNet/blob/main/LICENSE
|
||||
|
|
|
|||
65
README.md
65
README.md
|
|
@ -2,68 +2,41 @@
|
|||
|
||||
Run Stable Diffusion on your machine with a nice UI without any hassle!
|
||||
|
||||
|
||||
## Setup & Usage
|
||||
|
||||
Visit the wiki for [Setup](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup) and [Usage](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Usage) instructions, checkout the [FAQ](https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/FAQ) page if you face any problems, or create a new issue!
|
||||
|
||||
|
||||
## Contributing
|
||||
|
||||
Contributions are welcome! **Create a discussion first of what the problem is and what you want to contribute (before you implement anything)**
|
||||
## Features
|
||||
|
||||
This repository provides multiple UIs for you to play around with stable diffusion:
|
||||
|
||||
### AUTOMATIC1111
|
||||
### [AUTOMATIC1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||
|
||||
[AUTOMATIC1111's fork](https://github.com/AUTOMATIC1111/stable-diffusion-webui) is imho the most feature rich yet elegant UI:
|
||||
|
||||
- Text to image, with many samplers and even negative prompts!
|
||||
- Image to image, with masking, cropping, in-painting, out-painting, variations.
|
||||
- GFPGAN, RealESRGAN, LDSR, CodeFormer.
|
||||
- Loopback, prompt weighting, prompt matrix, X/Y plot
|
||||
- Live preview of the generated images.
|
||||
- Highly optimized 4GB GPU support, or even CPU only!
|
||||
- Textual inversion allows you to use pretrained textual inversion embeddings
|
||||
- [Full feature list here](https://github.com/AUTOMATIC1111/stable-diffusion-webui-feature-showcase)
|
||||
[Full feature list here](https://github.com/AUTOMATIC1111/stable-diffusion-webui-feature-showcase), Screenshots:
|
||||
|
||||
| Text to image | Image to image | Extras |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  | 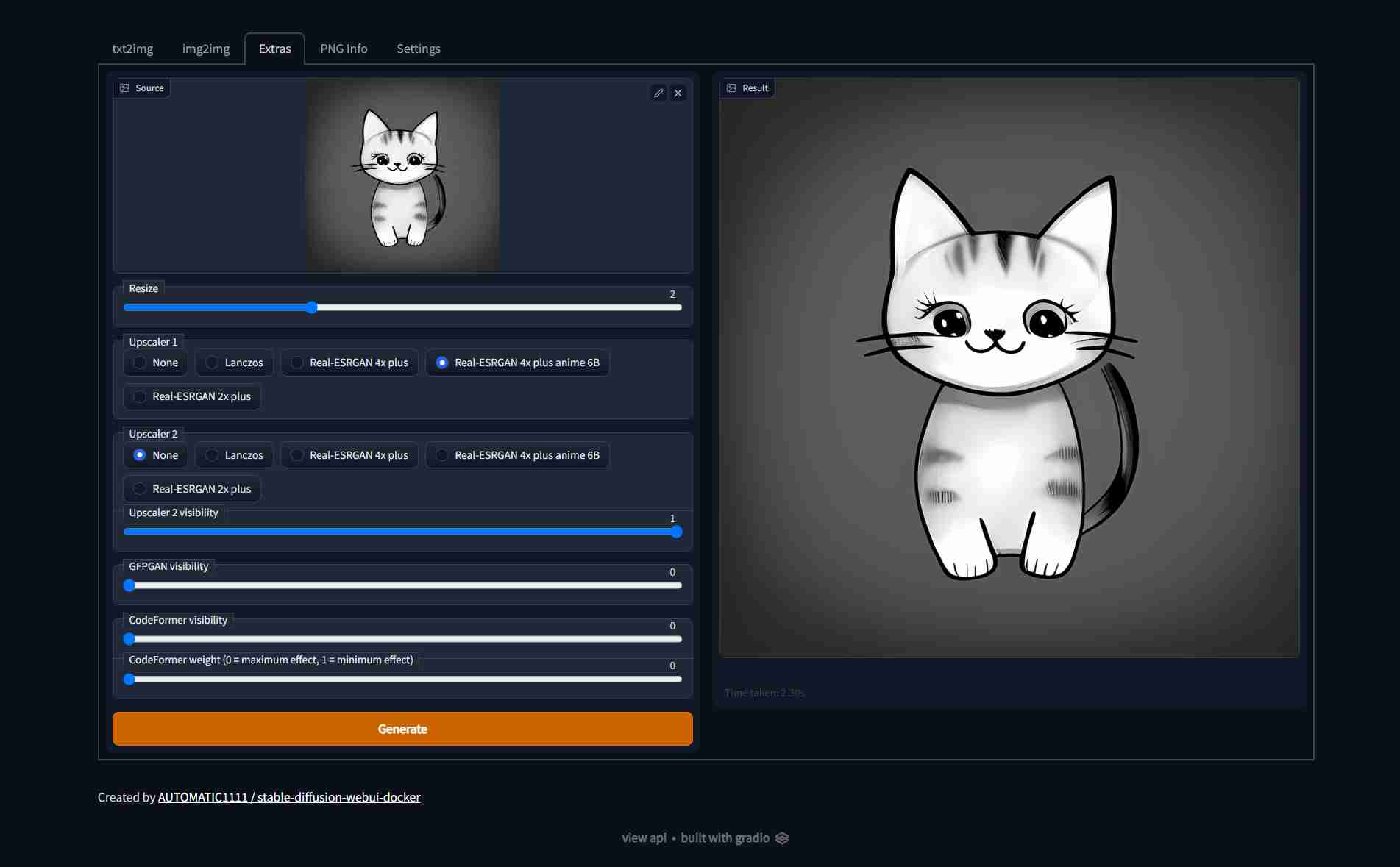 |
|
||||
|
||||
### hlky (sd-webui / sygil-webui)
|
||||
### [InvokeAI (lstein)](https://github.com/invoke-ai/InvokeAI)
|
||||
|
||||
[hlky's fork](https://github.com/Sygil-Dev/sygil-webui) is one of the most popular UIs, with many features:
|
||||
|
||||
- Text to image, with many samplers
|
||||
- Image to image, with masking, cropping, in-painting, variations.
|
||||
- GFPGAN, RealESRGAN, LDSR, GoBig, GoLatent
|
||||
- Loopback, prompt weighting
|
||||
- 6GB or even 4GB GPU support!
|
||||
- [Full feature list here](https://github.com/Sygil-Dev/sygil-webui/blob/master/README.md)
|
||||
|
||||
Screenshots:
|
||||
|
||||
| Text to image | Image to image | Image Lab |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  | 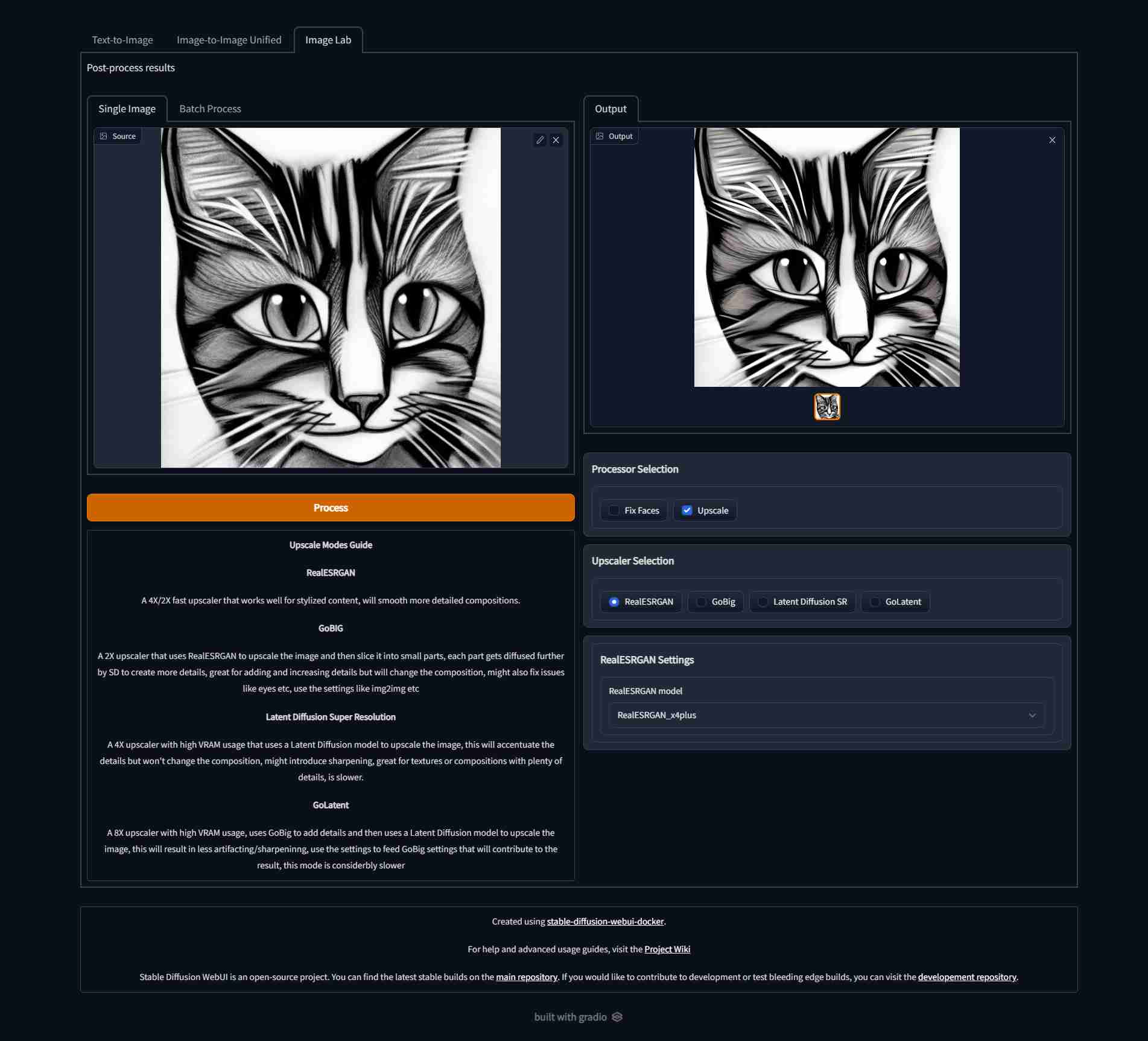 |
|
||||
|
||||
|
||||
|
||||
### lstein (InvokeAI)
|
||||
|
||||
[lstein's fork](https://github.com/invoke-ai/InvokeAI) is one of the earliest with a wonderful WebUI.
|
||||
- Text to image, with many samplers
|
||||
- Image to image
|
||||
- 4GB GPU support
|
||||
- More coming!
|
||||
- [Full feature list here](https://github.com/invoke-ai/InvokeAI#features)
|
||||
[Full feature list here](https://github.com/invoke-ai/InvokeAI#features), Screenshots:
|
||||
|
||||
| Text to image | Image to image | Extras |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  |  |
|
||||
|
||||
### [Sygil (sd-webui / hlky)](https://github.com/Sygil-Dev/sygil-webui)
|
||||
|
||||
[Full feature list here](https://github.com/Sygil-Dev/sygil-webui/blob/master/README.md), Screenshots:
|
||||
|
||||
| Text to image | Image to image | Image Lab |
|
||||
| ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
|  |  |  |
|
||||
|
||||
## Contributing
|
||||
|
||||
Contributions are welcome! **Create a discussion first of what the problem is and what you want to contribute (before you implement anything)**
|
||||
|
||||
## Disclaimer
|
||||
|
||||
|
|
@ -75,10 +48,8 @@ This license of this software forbids you from sharing any content that violates
|
|||
|
||||
Special thanks to everyone behind these awesome projects, without them, none of this would have been possible:
|
||||
|
||||
- [hlky/stable-diffusion-webui](https://github.com/hlky/stable-diffusion-webui)
|
||||
- [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||
- [lstein/stable-diffusion](https://github.com/lstein/stable-diffusion)
|
||||
- [InvokeAI](https://github.com/invoke-ai/InvokeAI)
|
||||
- [Sygil-webui](https://github.com/Sygil-Dev/sygil-webui)
|
||||
- [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
|
||||
- [hlky/sd-enable-textual-inversion](https://github.com/hlky/sd-enable-textual-inversion)
|
||||
- [devilismyfriend/latent-diffusion](https://github.com/devilismyfriend/latent-diffusion)
|
||||
- [Hafiidz/latent-diffusion](https://github.com/Hafiidz/latent-diffusion)
|
||||
- and many many more.
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ services:
|
|||
<<: *base_service
|
||||
profiles: ["auto"]
|
||||
build: ./services/AUTOMATIC1111
|
||||
image: sd-auto:19
|
||||
image: sd-auto:21
|
||||
environment:
|
||||
- CLI_ARGS=--allow-code --medvram --xformers --enable-insecure-extension-access
|
||||
|
||||
|
|
@ -38,20 +38,27 @@ services:
|
|||
environment:
|
||||
- CLI_ARGS=--no-half --precision full
|
||||
|
||||
hlky:
|
||||
sygil: &sygil
|
||||
<<: *base_service
|
||||
profiles: ["hlky"]
|
||||
build: ./services/hlky/
|
||||
image: sd-hlky:10
|
||||
profiles: ["sygil"]
|
||||
build: ./services/sygil/
|
||||
image: sd-sygil:13
|
||||
environment:
|
||||
- CLI_ARGS=--optimized-turbo
|
||||
- USE_STREAMLIT=0
|
||||
|
||||
lstein:
|
||||
sygil-sl:
|
||||
<<: *sygil
|
||||
profiles: ["sygil-sl"]
|
||||
environment:
|
||||
- USE_STREAMLIT=1
|
||||
|
||||
|
||||
invoke:
|
||||
<<: *base_service
|
||||
profiles: ["lstein"]
|
||||
build: ./services/lstein/
|
||||
image: sd-lstein:8
|
||||
profiles: ["invoke"]
|
||||
build: ./services/invoke/
|
||||
image: sd-invoke:11
|
||||
environment:
|
||||
- PRELOAD=true
|
||||
- CLI_ARGS=--max_loaded_models=1
|
||||
- CLI_ARGS=
|
||||
|
|
|
|||
|
|
@ -79,7 +79,7 @@ git reset --hard ${SHA}
|
|||
pip install -r requirements_versions.txt
|
||||
EOF
|
||||
|
||||
RUN pip install opencv-python-headless
|
||||
RUN pip install opencv-python-headless transformers==4.24.0
|
||||
|
||||
COPY . /docker
|
||||
|
||||
|
|
|
|||
|
|
@ -1,8 +1,8 @@
|
|||
{
|
||||
"outdir_samples": "/output",
|
||||
"outdir_txt2img_samples": "/output/txt2img-images",
|
||||
"outdir_img2img_samples": "/output/img2img-images",
|
||||
"outdir_extras_samples": "/output/extras-images",
|
||||
"outdir_samples": "",
|
||||
"outdir_txt2img_samples": "/output/txt2img",
|
||||
"outdir_img2img_samples": "/output/img2img",
|
||||
"outdir_extras_samples": "/output/extras",
|
||||
"outdir_txt2img_grids": "/output/txt2img-grids",
|
||||
"outdir_img2img_grids": "/output/img2img-grids",
|
||||
"outdir_save": "/output/saved",
|
||||
|
|
|
|||
|
|
@ -52,8 +52,6 @@ for to_path in "${!MOUNTS[@]}"; do
|
|||
echo Mounted $(basename "${from_path}")
|
||||
done
|
||||
|
||||
mkdir -p /output/saved /output/txt2img-images/ /output/img2img-images /output/extras-images/ /output/grids/ /output/txt2img-grids/ /output/img2img-grids/
|
||||
|
||||
if [ -f "/data/config/auto/startup.sh" ]; then
|
||||
pushd ${ROOT}
|
||||
. /data/config/auto/startup.sh
|
||||
|
|
|
|||
|
|
@ -1,51 +0,0 @@
|
|||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM continuumio/miniconda3:4.12.0
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN conda install python=3.8.5 && conda clean -a -y
|
||||
RUN conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch && conda clean -a -y
|
||||
|
||||
RUN apt-get update && apt install fonts-dejavu-core rsync gcc -y && apt-get clean
|
||||
|
||||
|
||||
ENV PIP_PREFER_BINARY=1 PIP_NO_CACHE_DIR=1
|
||||
|
||||
RUN <<EOF
|
||||
git config --global http.postBuffer 1048576000
|
||||
git clone https://github.com/Sygil-Dev/sygil-webui.git stable-diffusion
|
||||
cd stable-diffusion
|
||||
git reset --hard 091520bed06f913c9f432f9f47ccbe22b46068d7
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
RUN apt-get update && apt install libsndfile1 ffmpeg -y && apt-get clean
|
||||
|
||||
ARG BRANCH=dev SHA=18a3b809275c395b9a2730c78d6bc0f9b06671e1
|
||||
RUN <<EOF
|
||||
cd stable-diffusion
|
||||
git fetch
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
conda env update --file environment.yaml -n base
|
||||
conda clean -a -y
|
||||
EOF
|
||||
|
||||
# add info
|
||||
COPY . /docker/
|
||||
RUN <<EOF
|
||||
python /docker/info.py /stable-diffusion/frontend/frontend.py
|
||||
chmod +x /docker/mount.sh /docker/run.sh
|
||||
# streamlit
|
||||
sed -i -- 's/8501/7860/g' /stable-diffusion/.streamlit/config.toml
|
||||
EOF
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
ENV PYTHONPATH="${PYTHONPATH}:${PWD}" STREAMLIT_SERVER_HEADLESS=true USE_STREAMLIT=0 CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
|
||||
CMD /docker/mount.sh && /docker/run.sh
|
||||
60
services/invoke/Dockerfile
Normal file
60
services/invoke/Dockerfile
Normal file
|
|
@ -0,0 +1,60 @@
|
|||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM python:3.10-slim
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive PIP_EXISTS_ACTION=w PIP_PREFER_BINARY=1
|
||||
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip \
|
||||
pip install torch==1.12.0+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
|
||||
RUN apt-get update && apt-get install git -y && apt-get clean
|
||||
|
||||
RUN git clone https://github.com/invoke-ai/InvokeAI.git /stable-diffusion
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip <<EOF
|
||||
git reset --hard 5c31feb3a1096d437c94b6e1c3224eb7a7224a85
|
||||
git config --global http.postBuffer 1048576000
|
||||
pip install -r binary_installer/py3.10-linux-x86_64-cuda-reqs.txt
|
||||
EOF
|
||||
|
||||
|
||||
# patch match:
|
||||
# https://github.com/invoke-ai/InvokeAI/blob/main/docs/installation/INSTALL_PATCHMATCH.md
|
||||
RUN <<EOF
|
||||
apt-get update
|
||||
# apt-get install build-essential python3-opencv libopencv-dev -y
|
||||
apt-get install make g++ libopencv-dev -y
|
||||
apt-get clean
|
||||
cd /usr/lib/x86_64-linux-gnu/pkgconfig/
|
||||
ln -sf opencv4.pc opencv.pc
|
||||
EOF
|
||||
|
||||
ARG BRANCH=main SHA=ed9186b09950f2652a0b07c93a08490f475435f7
|
||||
RUN --mount=type=cache,target=/root/.cache/pip <<EOF
|
||||
git fetch
|
||||
git reset --hard
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
pip install -r binary_installer/py3.10-linux-x86_64-cuda-reqs.txt
|
||||
EOF
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip \
|
||||
pip install --force-reinstall opencv-python-headless && python3 -c "from patchmatch import patch_match"
|
||||
|
||||
|
||||
COPY . /docker/
|
||||
RUN <<EOF
|
||||
python3 /docker/info.py /stable-diffusion/frontend/dist/index.html
|
||||
touch ~/.invokeai
|
||||
EOF
|
||||
|
||||
|
||||
ENV ROOT=/stable-diffusion PYTHONPATH="${PYTHONPATH}:${ROOT}" PRELOAD=false CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
|
||||
ENTRYPOINT ["/docker/entrypoint.sh"]
|
||||
CMD python3 -u scripts/invoke.py --web --host 0.0.0.0 --port 7860 --config /docker/models.yaml --root_dir ${ROOT} --outdir /output/invoke ${CLI_ARGS}
|
||||
|
|
@ -5,7 +5,7 @@ set -Eeuo pipefail
|
|||
declare -A MOUNTS
|
||||
|
||||
# cache
|
||||
MOUNTS["/root/.cache"]=/data/.cache
|
||||
MOUNTS["/root/.cache"]=/data/.cache/
|
||||
|
||||
# ui specific
|
||||
MOUNTS["${ROOT}/models/codeformer"]=/data/Codeformer/
|
||||
|
|
@ -15,16 +15,16 @@ MOUNTS["${ROOT}/models/gfpgan/weights"]=/data/.cache/
|
|||
|
||||
MOUNTS["${ROOT}/models/realesrgan"]=/data/RealESRGAN/
|
||||
|
||||
MOUNTS["${ROOT}/models/bert-base-uncased"]=/data/.cache/huggingface/transformers
|
||||
MOUNTS["${ROOT}/models/openai/clip-vit-large-patch14"]=/data/.cache/huggingface/transformers
|
||||
MOUNTS["${ROOT}/models/CompVis/stable-diffusion-safety-checker"]=/data/.cache/huggingface/transformers
|
||||
MOUNTS["${ROOT}/models/bert-base-uncased"]=/data/.cache/huggingface/transformers/
|
||||
MOUNTS["${ROOT}/models/openai/clip-vit-large-patch14"]=/data/.cache/huggingface/transformers/
|
||||
MOUNTS["${ROOT}/models/CompVis/stable-diffusion-safety-checker"]=/data/.cache/huggingface/transformers/
|
||||
|
||||
|
||||
MOUNTS["${ROOT}/embeddings"]=/data/embeddings/
|
||||
|
||||
# hacks
|
||||
MOUNTS["/opt/conda/lib/python3.10/site-packages/facexlib/weights"]=/data/.cache/
|
||||
MOUNTS["${ROOT}/models/clipseg"]=/data/.cache/invoke/clipseg/
|
||||
|
||||
|
||||
for to_path in "${!MOUNTS[@]}"; do
|
||||
set -Eeuo pipefail
|
||||
from_path="${MOUNTS[${to_path}]}"
|
||||
|
|
@ -40,7 +40,8 @@ for to_path in "${!MOUNTS[@]}"; do
|
|||
done
|
||||
|
||||
if "${PRELOAD}" == "true"; then
|
||||
python3 -u scripts/preload_models.py --no-interactive --root . --config_file /docker/models.yaml
|
||||
set -Eeuo pipefail
|
||||
python3 -u scripts/preload_models.py --no-interactive --root ${ROOT} --config_file /docker/models.yaml
|
||||
fi
|
||||
|
||||
exec "$@"
|
||||
|
|
@ -1,49 +0,0 @@
|
|||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM python:3.10-slim
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive PIP_EXISTS_ACTION=w PIP_PREFER_BINARY=1 PIP_NO_CACHE_DIR=1
|
||||
|
||||
|
||||
RUN pip install torch==1.13.0 torchvision --extra-index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
RUN apt-get update && apt-get install git -y && apt-get clean
|
||||
|
||||
RUN git clone https://github.com/invoke-ai/InvokeAI.git /stable-diffusion
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
|
||||
RUN <<EOF
|
||||
git reset --hard 2b7e3abe57963d199f1d825ddef87ae154c81045
|
||||
git config --global http.postBuffer 1048576000
|
||||
ln -sf environments-and-requirements/requirements-lin-cuda.txt requirements.txt
|
||||
pip install -r requirements.txt
|
||||
EOF
|
||||
|
||||
|
||||
ARG BRANCH=development SHA=a9aa4e45aa6f5d5a2aa385349131d8733dd380fa
|
||||
RUN <<EOF
|
||||
git fetch
|
||||
git reset --hard
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
pip install -r requirements.txt
|
||||
EOF
|
||||
|
||||
RUN pip install --force-reinstall opencv-python-headless==4.5.5.64
|
||||
|
||||
COPY . /docker/
|
||||
RUN <<EOF
|
||||
python3 /docker/info.py /stable-diffusion/frontend/dist/index.html
|
||||
touch ~/.invokeai
|
||||
EOF
|
||||
|
||||
|
||||
ENV ROOT=/stable-diffusion PRELOAD=false CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
|
||||
|
||||
ENTRYPOINT ["/docker/entrypoint.sh"]
|
||||
CMD python3 -u scripts/invoke.py --web --host 0.0.0.0 --port 7860 --config /docker/models.yaml --root_dir . --outdir /output ${CLI_ARGS}
|
||||
46
services/sygil/Dockerfile
Normal file
46
services/sygil/Dockerfile
Normal file
|
|
@ -0,0 +1,46 @@
|
|||
# syntax=docker/dockerfile:1
|
||||
|
||||
FROM python:3.8-slim
|
||||
|
||||
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive PIP_PREFER_BINARY=1
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip pip install torch==1.13.0 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
RUN apt-get update && apt install gcc libsndfile1 ffmpeg build-essential zip unzip git -y && apt-get clean
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip <<EOF
|
||||
git config --global http.postBuffer 1048576000
|
||||
git clone https://github.com/Sygil-Dev/sygil-webui.git stable-diffusion
|
||||
cd stable-diffusion
|
||||
git reset --hard 5291437085bddd16d752f811b6552419a2044d12
|
||||
pip install -r requirements.txt
|
||||
EOF
|
||||
|
||||
|
||||
ARG BRANCH=master SHA=5291437085bddd16d752f811b6552419a2044d12
|
||||
RUN --mount=type=cache,target=/root/.cache/pip <<EOF
|
||||
cd stable-diffusion
|
||||
git fetch
|
||||
git checkout ${BRANCH}
|
||||
git reset --hard ${SHA}
|
||||
pip install -r requirements.txt
|
||||
EOF
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip pip install transformers==4.24.0
|
||||
|
||||
# add info
|
||||
COPY . /docker/
|
||||
RUN <<EOF
|
||||
python /docker/info.py /stable-diffusion/frontend/frontend.py
|
||||
chmod +x /docker/mount.sh /docker/run.sh
|
||||
# streamlit
|
||||
sed -i -- 's/8501/7860/g' /stable-diffusion/.streamlit/config.toml
|
||||
EOF
|
||||
|
||||
WORKDIR /stable-diffusion
|
||||
ENV PYTHONPATH="${PYTHONPATH}:${PWD}" STREAMLIT_SERVER_HEADLESS=true USE_STREAMLIT=0 CLI_ARGS=""
|
||||
EXPOSE 7860
|
||||
|
||||
CMD /docker/mount.sh && /docker/run.sh
|
||||
|
|
@ -1,10 +1,11 @@
|
|||
# https://github.com/Sygil-Dev/sygil-webui/blob/master/configs/webui/webui_streamlit.yaml
|
||||
general:
|
||||
version: 1.24.6
|
||||
outdir: /output
|
||||
default_model: "Stable Diffusion v1.5"
|
||||
default_model_path: /data/StableDiffusion/v1-5-pruned-emaonly.ckpt
|
||||
outdir_txt2img: /output/txt2img-samples
|
||||
outdir_img2img: /output/img2img-samples
|
||||
outdir_txt2img: /output/txt2img
|
||||
outdir_img2img: /output/img2img
|
||||
outdir_img2txt: /output/img2txt
|
||||
optimized: True
|
||||
optimized_turbo: True
|
||||
Loading…
Reference in a new issue